Task System
The task layer provides a higher-level abstraction on top of the communication layer to hide the details of execution and communication from the user, while still delegating data management to the user. At this layer, computations are modeled as task graphs which can be created either statically as a complete graph or dynamically as the application progresses. The task system comprises of task graph, execution graph, and task scheduling process.
Task Graph
The task graph is the preferred choice for the processing of large-scale data. It simplifies the process of task parallelism and has the ability to dynamically determine the dependency between those tasks. The nodes in the task graph consist of task vertices and edges in which task vertices represent the computational units of an application and edges represent the communication edges between those computational units. In other words, it describes the details about how the data is consumed between those units. Each node in the task graph holds the information about the input and its output. The task graph is converted into an execution graph once the actual execution takes place.
Task Graph in Twister2
The task layer provides a higher-level abstraction on top of the communication layer to hide the underlying details of the execution and communication from the user. Computations are modeled as task graphs in the task layer which could be created either statically or dynamically. A node in the task graph represents a task whereas an edge represents the communication link between the vertices. Each node in the task graph holds the information about the input and its output. A task could be long-running (streaming graph) or short-running (dataflow graph without loops) depending on the type of application. A task graph 'TG' generally consists of set of Task Vertices'TV' and Task Edges (TE) which is mathematically denoted as Task Graph
(TG) -> (TV, TE)
Static and Dynamic Task Graphs
The task graphs can be defined in two ways namely static and dynamic task graph.
- Static task graph - the structure of the complete task graph is known at compile time.
- Dynamic task graph - the structure of the task graph does not know at compile time and the program dynamically define the structure of the task graph during run time.
The following three essential points should be considered while creating and scheduling the task instances of the task graph.
- Task Decomposition - Identify independent tasks which can execute concurrently
- Group tasks - Group the tasks based on the dependency of other tasks.
- Order tasks - Order the tasks which will satisfy the constraints of other tasks.
(Reference: Patterns for Parallel Programming, Chapter 3 (2) & https://patterns.eecs.berkeley.edu/?page_id=609)
Directed Task Graph and Undirected Task Graph
There are two types of task graphs namely directed task graph and undirected task graph. In directed task graph, the edges in the task graph that connects the task vertexes have a direction as shown in Fig.1 whereas in undirected task graph, the edges in the task graph that connects the task vertexes have no direction as shown in Fig 2. The present task system supports only directed dataflow task graph.
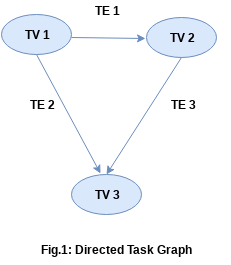
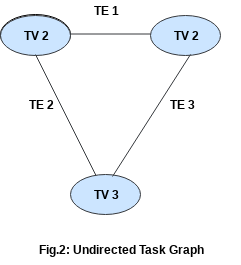
Streaming Task Graph
Stream refers the process of handling unbounded sequence of data units. The streaming application that can continuosly consumes input stream units and produces the output stream units. The streaming task graph is mainly responsible for building and executing the streaming applications.
Batch Task Graph
Batch processing refers the process of handling bounded sequence of data units. Batch applications mainly consumes bounded data units and produces the data units. The batch task graph is mainly responsible for building and executing the batch applications.
Task Graph in Twister2
The task graph system in Twister2 is mainly aimed to support the directed dataflow task graph which consists of task vertices and task edges.
- The task vertices represent the source and target task vertex
- The task edge represent the edges to connect the task vertices
The task graph in Twister2
- supports iterative data processing - For example, in K-Means clustering algorithm, at the end of every iteration, data points and centroids are stored in the DataSet which will be used for the next iteration
- It doesn’t allow loops or self-loops or cycles
It describes the details about how the data is consumed between the task vertices.
- Source Task - It extends the BaseSource and implements the Receptor interface which is given below.
- Compute Task - It implements the IFunction interface which is given below.
- Sink Task - It extends the BaseSink and implements the Collector interface.
Task Scheduling
Task Scheduling is the process of scheduling the tasks into the cluster resources in a manner that minimizes the task completion time and utilizes the resources effectively. The other main functional requirements of task scheduling are scalability, dynamism, time and cost efficiency, handling different types of processing models, data, and jobs, etc. The main objective of the task scheduling is scheduling the task instances in an appropriate order to suitable/appropriate cluster nodes. The task scheduling algorithms are broadly classified into two types namely static task scheduling algorithms and dynamic task scheduling algorithms. The task scheduler in twister2 is designed in a way such that it is able to handle both streaming and batch tasks. It supports the following task scheduling algorithms namely RoundRobin, FirstFit, and DataLocality.
RoundRobin Task Scheduling & DataLocality Aware Task Scheduling
- Homogeneous Containers -> Homogeneous Task Instances
FirstFit Task Scheduling
- Heterogeneous Containers -> Heterogeneous Task Instances
Implementation
The task scheduler has the main class named TaskScheduler which implements the base interface ITaskScheduler that consists of two main methods namely initialize and schedule methods to initialize the taskgraph configuration and schedule the taskgraph based on the workers information available in the resource plan.
edu.iu.dsc.tws.api.compute.schedule.ITaskScheduler
has the following methods namely
initialize (Config config)
schedule(DataflowTaskGraph graph, WorkerPlan plan)
The TaskScheduler is responsible for invoking the respective schedulers based on the type of task and the scheduling mode. If it is a streaming task, it will invoke the scheduleStreamingTask method whereas if it is a batch task it will invoke the scheduleBatchTask method.
edu.iu.dsc.tws.tsched.taskscheduler.TaskScheduler
has the following methods such as
scheduleStreamingTask()
scheduleBatchTask()
scheduleBatchGraphs()
generateTaskSchedulePlan(String classname)
Map generateTaskSchedulePlans(String className)
The scheduleStreamingTask and scheduleBatchTask call the generateTaskSchedulePlan with the scheduling class name as an argument which is specified in the task.yaml. The generateTaskSchedulePlan dynamically load the respective task schedulers (roundrobin, firstfit, or datalocalityaware) and access the initialize and schedule methods in the task schedulers to generate the task schedule plan.
Proto file
The task scheduler has the protobuf file named taskscheduleplan.proto in the proto directory. It considers both the soft (CPU, disk) and hard (RAM) constraints which generates the task schedule plan in the format of Google Protobuf object. The proto file consists of the following details as follows. The resource object represents the values of cpu, memory, and disk of the resources. The task instance plan holds the task id, task name, task index, and container object. The container plan consists of container id, task instance plan, required and scheduled resource of the container. The task schedule plan holds the jobid or the taskgraph id and the container plan. The task schedule plan list is mainly responsible for holding the taskschedule of the batch tasks.
message Resource {
double availableCPU = 1;
double availableMemory = 2;
double availableDisk = 3;
}
message TaskInstancePlan {
int32 taskid = 1;
string taskname = 2;
int32 taskindex = 3;
Resource resource = 4;
}
message ContainerPlan {
int32 containerid = 1;
repeated TaskInstancePlan taskinstanceplan = 2;
Resource requiredresource = 3;
Resource scheduledresource = 4;
}
message TaskSchedulePlan {
int32 jobid = 1;
repeated ContainerPlan containerplan = 2;
}
message TaskSchedulePlanList {
int32 jobid = 1;
repeated TaskSchedulePlan taskscheduleplan = 2;
}
YAML file
The task scheduler has task.yaml in the config directory. The task scheduler mode represents either 'roundrobin' or 'firstfit' or 'datalocalityaware'. The default task instance represents the default memory, disk, and cpu values assigned to the task instances. The default container padding value represents the percentage of values to be added to each container. The default container instance value represents the default size of memory, disk, and cpu of the container. The task parallelism represents the default parallelism value assigned to each task instance. The task type represents the streaming or batch task. The task scheduler dynamically loads the respective streaming and batch task schedulers based on the configuration values specified in the task.yaml. The sample values of yaml file is given below:
``yaml
# Task scheduling mode for the streaming jobs "roundrobin" or "firstfit" or "datalocalityaware" or "userdefined"
twister2.taskscheduler.streaming: "roundrobin"
# Task Scheduler class for the round robin streaming task scheduler
twister2.taskscheduler.streaming.class: "edu.iu.dsc.tws.tsched.streaming.roundrobin.RoundRobinTaskScheduler"
# Task scheduling mode for the batch jobs "roundrobin" or "datalocalityaware" or "userdefined" or "batchscheduler"
twister2.taskscheduler.batch: "batchscheduler"
# Task Scheduler class for the batch task scheduler
twister2.taskscheduler.batch.class: "edu.iu.dsc.tws.tsched.batch.batchscheduler.BatchTaskScheduler"
# Number of task instances to be allocated to each worker/container
twister2.taskscheduler.task.instances: 2
# Ram value to be allocated to each task instance
twister2.taskscheduler.task.instance.ram: 512.0
# Disk value to be allocated to each task instance
twister2.taskscheduler.task.instance.disk: 500.0
# CPU value to be allocated to each task instance
twister2.taskscheduler.instance.cpu: 2.0
# Prallelism value to each task instance
twister2.taskscheduler.task.parallelism: 2
# Task type to each submitted job by default it is "streaming" job.
twister2.taskscheduler.task.type: "streaming"
# number of threads per worker
twister2.exector.worker.threads: 1
# name of the batch executor
twister2.executor.batch.name: "edu.iu.dsc.tws.executor.threading.BatchSharingExecutor2"
# number of tuples executed at a single pass
twister2.exector.instance.queue.low.watermark: 10000
``
Batch Task Scheduler
Batch Task Scheduler is able to handle and schedule both single task graph as well as multiple dependent task graphs. The main constraint considered in the batch task scheduler is specify the same parallelism value for the dependent tasks in the task graphs. It schedule the tasks in a round robin fashion but, while scheduling the dependent tasks it considers the data locality of the input data from the parent tasks and schedule the tasks in a round robin fashion to the workers.
``yaml
#Batch Task Scheduler
twister2.taskscheduler.batch: "batchscheduler"
#Task Scheduler class for the batch task scheduler
twister2.taskscheduler.batch.class: "edu.iu.dsc.tws.tsched.batch.batchscheduler.BatchTaskScheduler"
``
User-Defined Task Scheduler
The task scheduler in Twister2 supports the user-defined task scheduler. The user-defined task scheduler has to implement the ITaskScheduler interface. The user has to specify the task scheduler as "user-defined" with the corresponding "user-defined" task scheduler class name.
``yaml
#User-defined Streaming Task Scheduler
twister2.streaming.taskscheduler: "user-defined"
# Task Scheduler for the userDefined Streaming Task Scheduler
#twister2.taskscheduler.streaming.class: "edu.iu.dsc.tws.tsched.userdefined.UserDefinedTaskScheduler"
# Task Scheduler for the userDefined Batch Task Scheduler
#twister2.taskscheduler.batch.class: "edu.iu.dsc.tws.tsched.userdefined.UserDefinedTaskScheduler"
``
Other task schedulers and their respective class names
The other task schedulers and their respective class names are given below. The user have to specify the respective scheduler mode and their corresponding class names.
``yaml
# Task Scheduler for the Data Locality Aware Streaming Task Scheduler
#twister2.taskscheduler.streaming.class: "edu.iu.dsc.tws.tsched.streaming.datalocalityaware.DataLocalityStreamingTaskScheduler"
# Task Scheduler for the FirstFit Streaming Task Scheduler
#twister2.taskscheduler.streaming.class: "edu.iu.dsc.tws.tsched.streaming.firstfit.FirstFitStreamingTaskScheduler"
# Task Scheduler class for the round robin batch task scheduler
#twister2.taskscheduler.batch.class: "edu.iu.dsc.tws.tsched.batch.roundrobin.RoundRobinBatchTaskScheduler"
# Task Scheduler for the Data Locality Aware Batch Task Scheduler
#twister2.taskscheduler.batch.class: "edu.iu.dsc.tws.tsched.batch.datalocalityaware.DataLocalityBatchTaskScheduler"
``
Execution
Task executor is the component which is responsible for executing the task graph. A process model or a hybrid model with threads can be used for execution which is based on the system specification. It is important to handle both I/O and task execution within a single execution module so that the framework can achieve the best possible performance by overlapping I/O and computations. The execution is responsible for managing the scheduled tasks and activating them with data coming from the message layer. Unlike in MPI based applications where threads are created equal to the number of CPU cores, big data systems typically employ more threads than the cores available to facilitate I/O operations.
- Task Executor is the component which is responsible for executing the tasks that are submitted
through the task scheduler in each worker
- It uses threads to execute a given task plan.
- It allows to run one or more executors run on each worker node
- It will queue the tasks and execute the tasks based on the submitted order.
- The task executor will receive the tasks as serialized objects and it will deserialize the objects before processing them.
- A thread pool will be maintained by the task executors to manage the core in an optimal manner.
- The size of the thread pool will be determined by the number of cores that are available to the executor.
Types of Task Executors
- Task Executor is implemented with two types of executors namely
- Batch Sharing Task Executor
- Streaming Sharing Task Executor
- Task Executor invokes the appropriate task executors based on the type of the task graph.
- Batch Sharing Task Executor terminate after the computation ends whereas Streaming Sharing Task Executor runs continuously.
Task Executor Call
public Executor(Config cfg, int wId, ExecutionPlan executionPlan, TWSChannel channel,
OperationMode operationMode)
Execution Graph
- Execution graph is a transformation of the user-defined task graph created by the framework to be executed on the cluster.
- Execution graph will be scheduled to the available resource by the task scheduler.
Execution Graph Builder
- The Task Executor call the ExecutionGraphBuilder and get the ExecutionPlan for the scheduled taks in the workers.
ExecutionPlanBuilder executionPlanBuilder = new ExecutionPlanBuilder(
workerID, workerInfoList, communicator, this.checkpointingClient);
return executionPlanBuilder.build(config, graph, taskSchedulePlan);