Operator API
Twister2 supports a DataFlow model for operators. A DataFlow program models a computation as a graph with nodes of the graph doing user-defined computations and edges representing the communication links between the nodes. The data flowing through this graph is termed as events or messages. It is important to note that even though by definition dataflow programming means data is flowing through a graph, it may not necessarily be the case physically, especially in batch applications. Big data systems employ different APIs for creating the dataflow graph. For example, Flink and Spark provide distributed dataset-based APIs for creating the graph while systems such as Storm and Hadoop provide task-level APIs.
We support the following operators for batch and streaming applications. The operators can go from M to N tasks, M to 1 task or 1 to N tasks.
Twister2 Batch Operations
The batch operators work on set of input data from a source. All this input data will be processed in a single operator.
| Operator | Semantics |
|---|---|
| Reduce | M tasks to 1, reduce the values to a single value |
| Gather | M tasks to 1, gather the values from M tasks |
| Broadcast | 1 task to N, Broadcast a value from 1 to N tasks |
| Partition | M tasks to N, distribute the values in M tasks to N tasks according to a user-specified criteria |
| AllReduce | M tasks to N, Reduce values from N tasks and broadcast to N tasks |
| AllGather | M tasks to N, Gathers values from M tasks and broadcast to N tasks |
| KeyedReduce | M tasks to N, Reduce values of a certain key, only available with Windowed data sets |
| KeyedGather | M tasks to N, Gathers according to a user-specified Key, keys can be sorted, only available with Windowed data sets |
| Join | M tasks to N, Jons values based on a user-specified key |
Twister2 Streaming Operations
The streaming operators work on single data items.
| Operator | Semantics |
|---|---|
| Reduce | M tasks to 1, reduce the values to a single value |
| Gather | M tasks to 1, gather the values from M tasks |
| Broadcast | 1 task to N, Broadcast a value from 1 to N tasks |
| Partition | M tasks to N, distribute the values in M tasks to N tasks according to a user-specified criteria |
| AllReduce | M tasks to N, Reduce values from N tasks and broadcast to N tasks |
| AllGather | M tasks to N, Gathers values from M tasks and broadcast to N tasks |
| KeyedReduce | M tasks to N, Reduce values of a certain key, only available with Windowed data sets |
| KeyedGather | M tasks to N, Gathers according to a user-specified Key, keys can be sorted, only available with Windowed data sets |
| Join | M tasks to N, Joins values based on a user-specified key |
Dataflow communications are overlaid on top of worker processes using logical ids.
We support both streaming and batch versions of these operations.
Reduce
The reduce operation collects data and performs and reduces them in a manner specified by the reduce
function, which can be specified. To look at an simple example let us assume that we are performing a reduce
operation on the values {1,2,3,4,5,6,7,8} if the function specified for the reduce operation was 'Sum'
the result would be 36, if the function used was 'Multiplication' the result would be 40320.
Since this reduce is taking place in an distributed environment the same function needs to be applied to data that is collected from several distributed workers. Which means there is a lot of communications involved in transferring data between distributed nodes. In order to make the communication as efficient as possible the reduce operation performs its reduction in a inverted binary tree structure. Lets look at a more detailed example to get an better idea about how this operation works. Please note that some details will be left out to simply the explanation.
Example:
In this example we have a distributed deployment which has 4 worker nodes named w-0 t0 w-3. The reduce example
that we are running has 8 source tasks and a single sink task (the task to which the reduction happens). The source
tasks are given logical id from 0 to 7, the sink task is given a logical id of 8.
How each task is assigned to workers will not be explained in this section. We assume that the following task-worker assignments are in place. The tree structure that is used by the reduce operation will take into account the task-worker assignments to optimize the operation. The diagram below show the assignments and the paths of communication
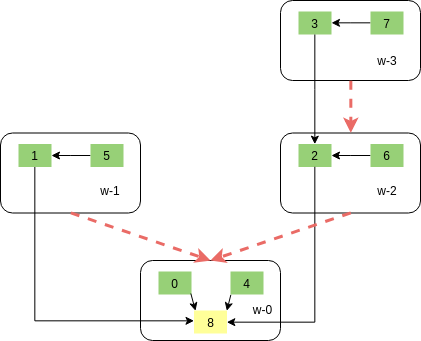
Black arrows in the diagram show the paths in which communication happens in the reduce operation. The inverted binary tress structure is more clear if you look at the red arrow. This structure allows the reduce operation to scale to large number of tasks very easily.
If we assume that each task generates a data array of {1,2,3} the final result after the reduce which will be available
at the sink task will be {8,16,24}. From the diagram it is clear that the sink task only receives values
from tasks 0,1,2,4. To further optimize the operation each task will perform partial reduce operations
before sending out data to the next destination. So the data that each task sends to the sink task will be as follows
for this example
- 0 -> 8 :
{1,2,3} - 1 -> 8 :
{2,4,6} - 2 -> 8 :
{4,8,12} - 4 -> 8 :
{1,2,3}
Gather
The gather operation is similar in construct to the reduce operation. However unlike the reduce operation which uses an reduction function to reduce collected values, the gather operation simply bundles them together. The structure in which the gather communication happens is similar to reduce which is done using an inverted binary tree.
Example:
Lets take the same example discussed in the Reduce operation. In the reduce example the final result at
the sink task with logical id 8 was {8,16,24}. In the gather since we collect all the data tht is sent from each
source task the final results received at the sink task would be a set of arrays, 1 array for each source task.
Final result at 8 -> {{1,2,3},{1,2,3},{1,2,3},{1,2,3},{1,2,3},{1,2,3},{1,2,3},{1,2,3}}
If you look at what each of the tasks that actually send messages to sink 8 they would be as follows.
Notice that the results are similar to the reduce operation.
- 0 -> 8 :
{1,2,3} - 1 -> 8 :
{{1,2,3},{1,2,3}} - 2 -> 8 :
{{1,2,3},{1,2,3},{1,2,3},{1,2,3}} - 4 -> 8 :
{1,2,3}
AllReduce
The BSP APIs are provided by Harp and MPI specification (OpenMPI).
The DataFlow operators are implemented by Twister2 as a Twister:Net library.