API Overview
Twsiter2 desing allows a user to access the lowest level APIs to the highest. This allows flexibility for programmers and building of more API's specific to application domains. These APIs allow users to program a distributed application according to the level of usability and performance needed. These API levels are highlighted in the figure below.
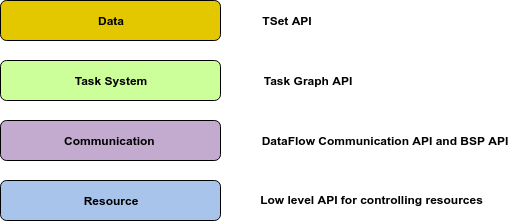
Data API (Based on TSets - Twister Set)
This is the highest level of API supported by Twister2 at this time. If you are familiar with Apache RDD API or Apache Flink API or Apache Beam API you will feel right at home with this API. It models a data as a distributed set and views processing as set of transformations on this distributed data.
Compute API
This API is similar to Apache Storm for streaming analytics and Apache Hadoop for batch analysis. It provides more flexibility to the programmer than the TSet API for some applications. We believe streaming applications can especially benefit from this flexible API.
Parallel Communicator API
This API gives access to the low level parallel communicators used in Twister2. It is the lowest level of abstraction for writing a parallel program in Twister2.
At this level a user can use the dataflow operators provided by Twister2 or BSP operators provided by MPI (if deployed with MPI) or Harp APIs.
Worker API
At the lowest level Twister2 provides access to a compute resource. Once a job is submitted it allocates set of resources and provides functions to discover these resources.
API Flexibility
API flexibility is a key goal in Twister2. The multiple levels of APIs provide a trade-off between usability and performance. The lowest levels of APIs are more flexible and performance while the higher level APIs provide more usability.

This design allows users to mix and match these APIs according to the requirements of the applications.