Architecture
Goal of Twister2 is to provide a layered approach for big data with independent components at each level to compose an application. The layers include: 1. Resource allocations 2. Data Access 3. Communication 4. Task System 5. Distributed Data
Among these communications, task system and data management are the core components of the system with the others providing auxiliary services. On top of these layers, one can develop higher-level APIs such as SQL interfaces. The following figure shows the runtime architecture of Twister2 with various components. Even though shows all the components in a single diagram, one can mix and match various components according to their needs. Fault tolerance and security are two aspects that affect all these components.
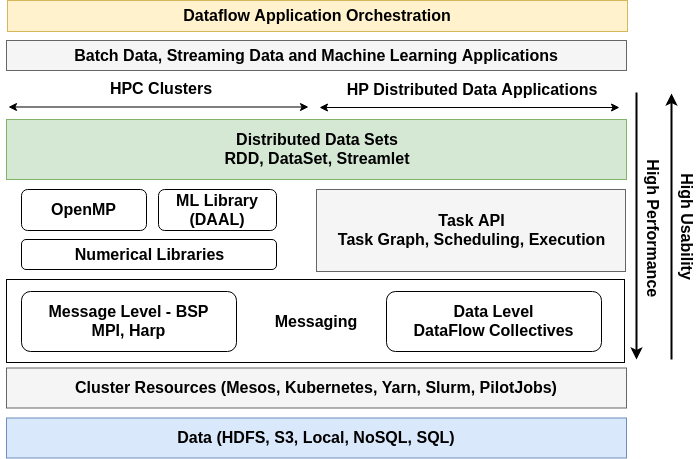
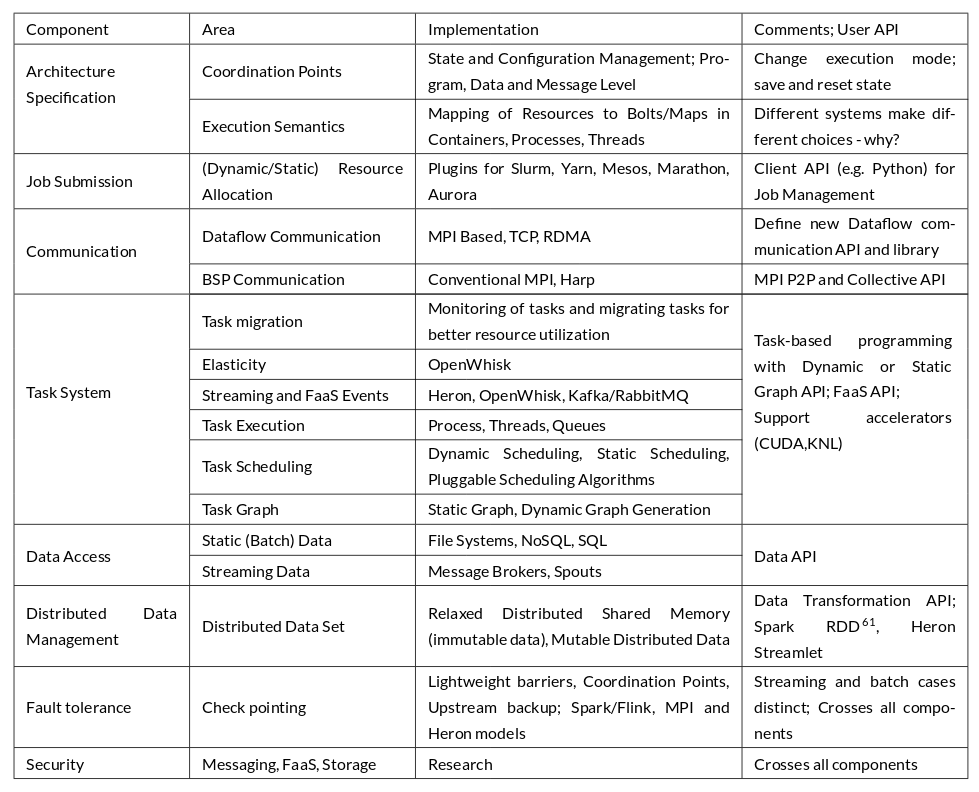
The following table gives a summary of various components, APIs, and implementation choices.
Resource provisioning component
The primary responsibility of this component is job submission and management. It provides abstractions to acquire resources and manage the life cycle of a parallel job. We have developed links to the following resource managers and would like to add others such as Yarn, Marathon in the future.
- Standalone
- Kubernetes
- Mesos
- Slurm
- Nomad
Twister2 jobs run in isolation without sharing any resources among jobs. Unlike in other big data systems such as Spark or Flink, Twister2 can be running in HPC or cloud environments.
Parallel and Distributed communication operators
Unlike other big data analytics systems, we recognize the importance of network communication operators for parallel applications and provide a set of abstractions and implementation that satisfy the needs of different applications. Both streaming operators and batch operators are provided. Three types of operator implementations are provided to the user.
- Twister:Net - a data level dataflow operator library for streaming and large scale batch analysis
- Harp - a BSP (Bulk Synchronous Processing) innovative collective framework for parallel applications and machine learning at the message level
- OpenMPI (HPC Environments only) at the message level
In other big data systems, communication operators are hidden behind high-level APIs. This design gives a priority to operator API’s and allows the development of different methods to optimize the performance while users can use low-level APIs to program high-performance applications. Twister:Net can use both socket based or MPI based (ISent/IRecv) to communicate allowing it to perform well on advanced hardware.
Task System
This component provides the abstractions to hide the execution details and an easy to program API for parallel applications. A user can create a streaming task graph or a batch task graph to analyze data. The abstractions have similarities to Storm and Hadoop APIs. Task system consists of the following major components.
Task Graph - Create dataflow graphs for streaming and batch analysis including iterative computations Task Scheduler - Schedule the task graph into cluster resources supporting different scheduling algorithms Executor - Batch and streaming executions
In Spark and Flink, this component is hidden from the user. Apache Storm and Flink API’s are at this level of abstraction. We allow pluggable executors and task schedulers to extend the capabilities of the system.
Distributed Data Abstraction
A typed distributed data abstraction, similar to Spark RDD, BEAM PCollections or Heron Streamlet is provided here. It can be used to program a data pipeline, a streaming application or iterative application.
- Iterative computations
- Streaming computations
- Data pipelines
In Twister2, iterations (for loops) are carried on each worker. Spark uses a central driver to control the iterations, which can lead to poor performance for applications with frequent iterations (less computation in an iteration). Flink uses the task graph itself to code the iterations (cyclic graphs) and doesn’t support nested iterations.
Data pipelines in Twister2 are similar to Flink or Spark. Twister2 is a pure streaming engine making it similar to Flink or Storm (not a minibatch system like Spark).
Auxiliary Components
Apart from the main futures, it provides the following components.
- Web UI for monitoring Jobs
- Connected DataFlow (Experimental), this is for workflow type jobs
- Data access API for connecting to different data sources (File systems)
APIs
Twister2 supports several APIs for programming an application. An application can use a mixed set of these APIs. The main APIs include
- TSet API (Similar to Spark).
- Task Graph-based API (Similar to Hadoop and Storm)
- Communications Operator API (BSP API and DataFlow operator API)
Twister2 supports the Storm API for programming a Storm application. The Twister2 native streaming API provides a richer set of operations than Storm API.
These concepts are widely discussed in the publications section
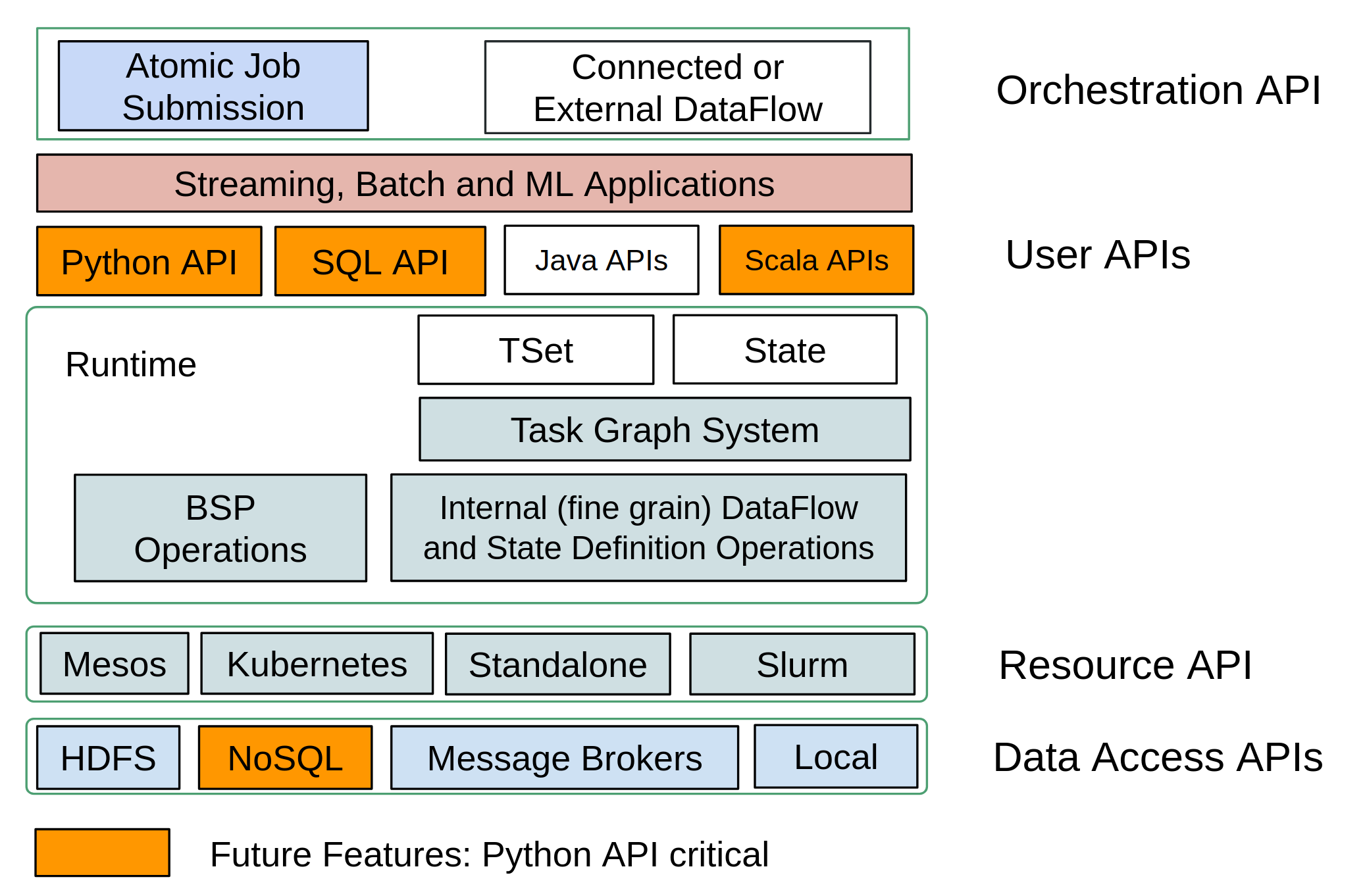
Twister2 Runtime
Each Twister2 job runs in isolation without any interference from other jobs. Because of this the distributed runtime of Twister2 is relevant to each job.
At the bottom of the Twister2 is the data access APIs. These APIs provide mechanisms to access data in file systems, message brokers and databases. Next we have the cluster resource management layer. Resource API is used for acquiring resources from an underlying resource manager such as Mesos or Kubernetes.
At the bottom of a Twister2 runtime job, there are a set of parallel operators. Twister2 supports both BSP style operators as in MPI and DataFlow style operators as in big-data systems.
The task system is on top of the DataFlow operators. They provide a Task Graph, Task Scheduler and an Executor. At the runtime, the user graph is converted to an execution graph and scheduled onto different workers. This graph is then executed by the executor using Threads.
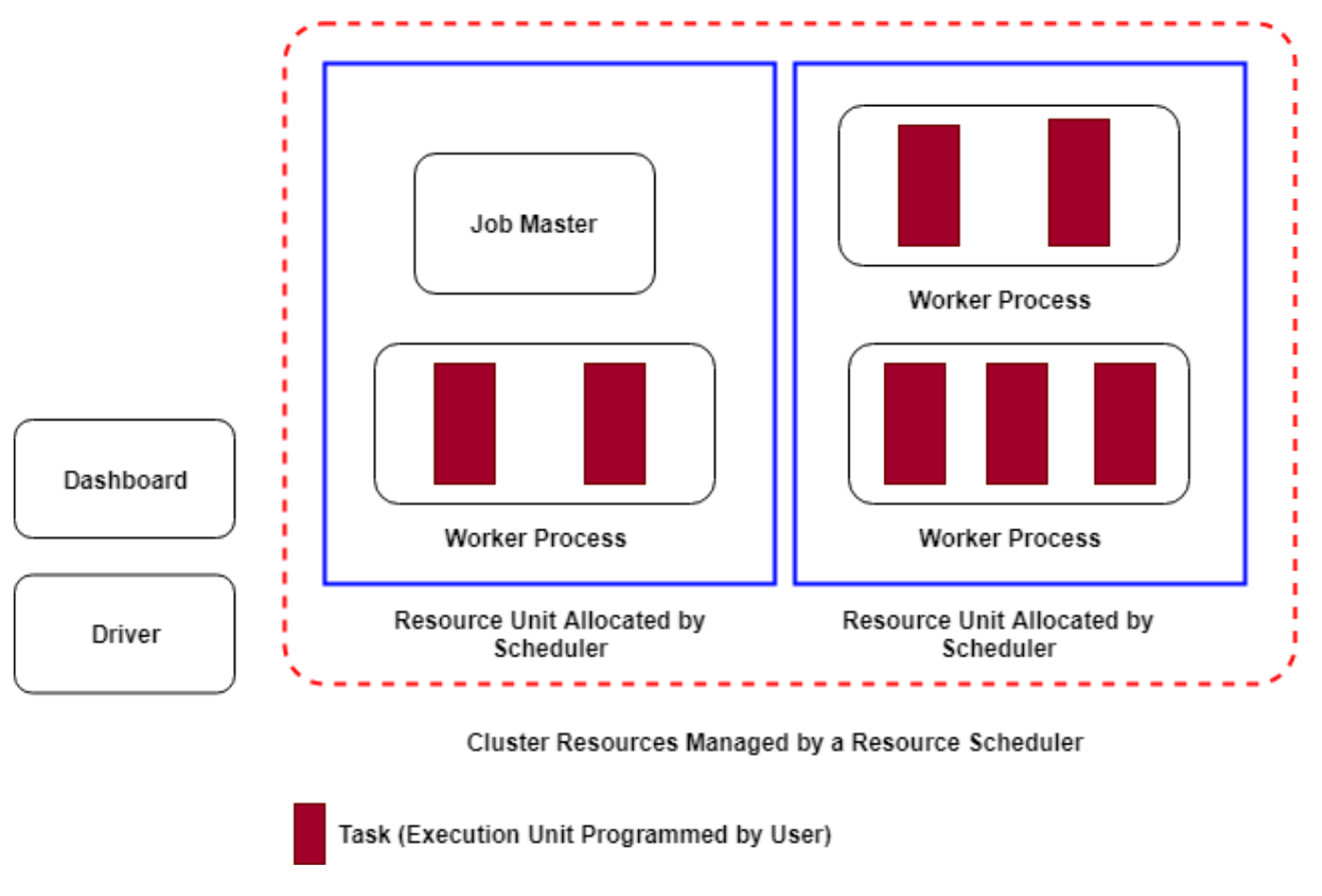
Twister2 spawns several processes when running a job.
- Driver - The program initiating the job
- Worker Process - A process spawn by resource manager for running the user code.
- Task - An execution unit of the program (A thread executes this unit)
- Job Master - One job master for each job
- Dashboard - A web service hosting the UI
The Job Life-Cycle
There are two modes of job submission for Twister2.
- Distributed mode
- Connected DataFlow mode (experimental)
Distributed mode
In Distributed mode, a user program is written as an IWorker implementation. The twister2 submit
command initiates the driver program written by the user.
First the program acquires the resources it needs. Then the user programmed IWorker is instantiated on the allocated resources. Once the IWorker is executed, it can execute the user program.
Behind the scenes the IWorkers use JobMaster to discover each other and establish network communications between them.
Once the Job completes, the workers finish execution and return the resources to the resource allocator.
Connected DataFlow mode
In Connected DataFlow mode, the program is written inside a Driver interface. This program is serialized and sent to the workers to execute. The Driver program written by the user runs in the JobMaster and controls the job execution.
Twister2 Runtime
Twister2 Runtime consists of the following main components.
- Job Submission Client
- Job Master
- Workers
Job Submission Client
This is the program that the user use to submit/terminate/modify Twister2 jobs. It may run in the cluster or outside of it in the user machine.
Job Master
Job Master manages the job related activities during job execution such as fault tolerance, life-cycle management, dynamic resource allocation, resource cleanup, etc.
Workers
The processes that perform the computations in a job.
Twister2 Dashboard:
Twister2 Dashboard is a web site that helps users to monitor their jobs. Only one instance of Dashboard runs in the cluster and it will provide data for all jobs running in the cluster. It is a long running service. It is installed and started once and it runs continually.
Following sections describe some of these components in detail.