concepts/task-system/task-scheduler/streaming
Streaming Schedulers
Round Robin Task Scheduler
RoundRobin Task Scheduler allocates the task instances of the task graph in a round robin fashion. For example, if there are 2 containers and 2 tasks with a task parallelism value of 4, task instance 0 of 1st task will go to container 1, task instance 1 of 1st task will go to container 2, task instance 3 of 1st task will go to container 1 and task instance 4 of 1st task will go to container 2. Similarly, task instance 0 of 2nd task will go to container 1, task instance 1 of 2nd task will go to container 2, task instance 3 of 1st task will go to container 1 and task instance 4 of 1st task will go to container 2
It generates the task schedule plan which consists of the containers (container plan) and the allocation of task instances (task instance plan) on those containers. The size of the container (memory, disk, and cpu) and the task instances (memory, disk, and cpu) are homogeneous in nature is shown in Fig.1.
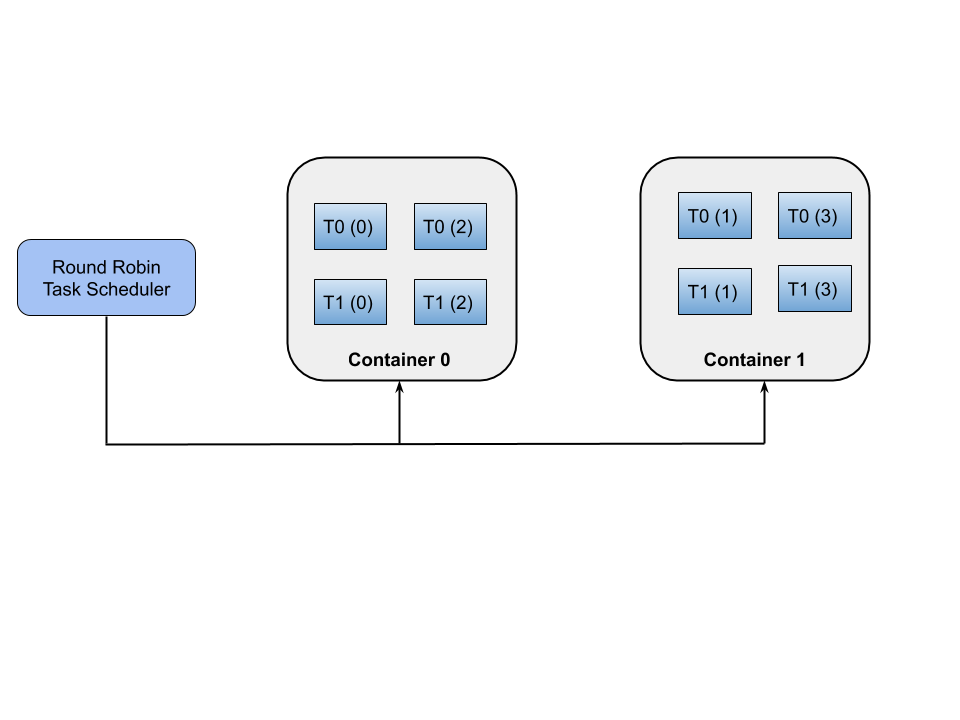
First, it will allocate the task instances into the logical container values and then it will calculate the required ram, disk, and cpu values for the task instances and the logical containers which is based on the task configuration values and the allocated worker values respectively.
The algorithm first gets the task vertex set of the taskgraph and send that task vertex set and the number of workers to the roundRobinSchedulingAlgorithm method for the logical allocation of the task instances to the logical container in a round robin fashion. Next, it assign the logical container size based on the default ram, disk, and cpu values specified in the TaskScheduler Context. Then, the algorithm unwraps the container instance map and finds out the task instances allocated to each container. Based on the task instances required ram, disk, and cpu it creates the required container object. If the worker has required ram, disk, and cpu value then it assigns those values to the containers otherwise, it will assign the calculated value of required ram, disk, and cpu value to the containers. Finally, the algorithm method pack the task instance plan and the container plan into the task schedule plan and return the same.
Round Robin Streaming Task Scheduler Source Code
First Fit Streaming Task Scheduler
FirstFit Task Scheduler allocates the task instances of the task graph in a heuristic manner. The main objective of the task scheduler is to reduce the total number of containers and support the heterogeneous containers and task instances allocation.
For example, if there are two tasks with parallelism value of 4, 1st task -> instance 0 will go to container 0, 1st task -> instance 1 will go to container 0, 2nd task -> instance 0 will go to container 0 (if the total task instance required values doesn't reach the maximum size of container 0. If the container has reached its maximum limit then it will allocate the 2nd task -> instance 1 will go to container 1. The size of the container (memory, disk, and cpu) and the task instances (memory, disk, and cpu) are heterogeneous in nature is shown in Fig.2.
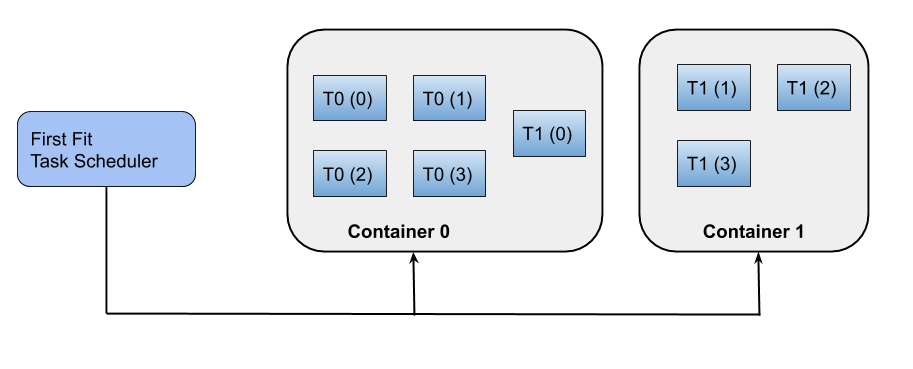
The initialize() method in the FirstFitStreamingTaskScheduler first initialize the task instance ram, disk, and cpu values with default task instance values specified in the TaskSchedulerContext. Next, it assign the logical container size based on the default ram, disk, and cpu values specified in the TaskScheduler Context. The schedule() method invokes the firstfitTaskScheduling method for the logical allocation of the task instances to the logical container. The assignInstancesToContainers() method receive the parallel task map and it first sorts the task map based on the requirements of the ram value. It allocates the task instances into the first container which has enough resources otherwise, it will allocate a new container to allocate the task instances.
First Fit Streaming Task Scheduler Source Code
Data Locality Streaming Task Scheduler
DataLocality Aware Task Scheduler allocates the task instances of the streaming task graph based on the locality of data. It calculates the distance between the worker nodes and the data nodes and allocate the streaming task instances to the worker nodes which are closer to the data nodes i.e. it takes lesser time to transfer/access the input data file. The data transfer time is calculated based on the network parameters such as bandwidth, latency, and size of the input file. It generates the task schedule plan which consists of the containers (container plan) and the allocation of task instances (task instance plan) on those containers. The size of the container (memory, disk, and cpu) and the task instances (memory, disk, and cpu) are homogeneous in nature. First, it computes the distance between the worker node and the datanodes and allocate the task instances into the logical container values and then it will calculate the required ram, disk, and cpu values for the task instances and the logical containers which is based on the task configuration values and the allocated worker values respectively. The allocation of task instances (task instance plan) based on the data locality based task scheduling is shown in Fig. 3.
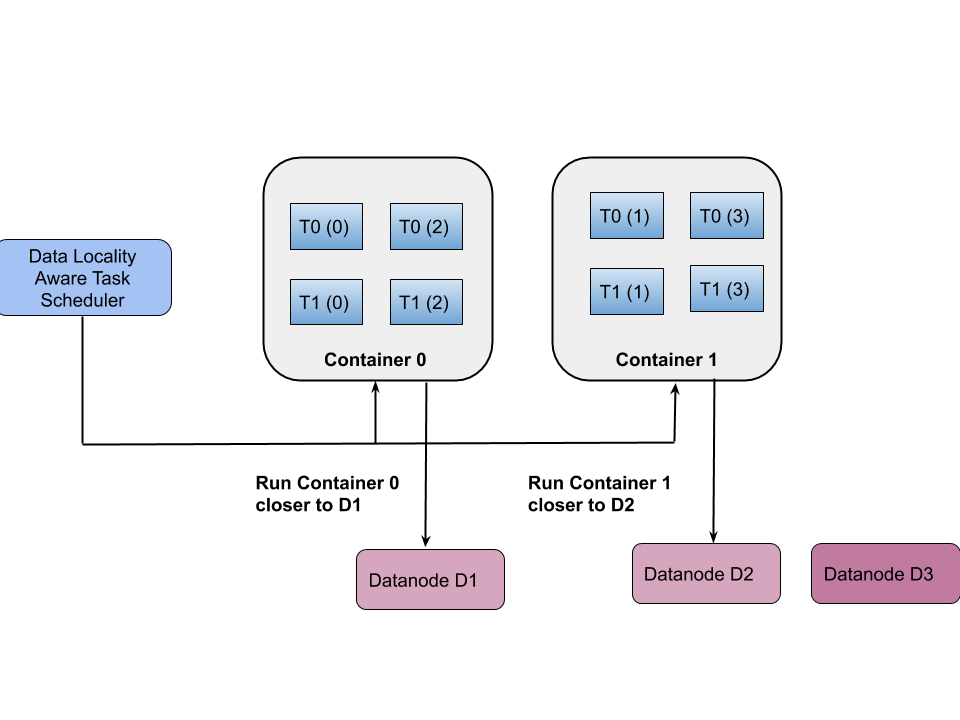
The DataLocalityStreamingTaskScheduler first initialize the ram, disk, and cpu values with default task instance values specified in the TaskSchedulerContext. The schedule() method invokes the DataLocalityStreamingTaskScheduling algorithm to perform the data locality based task scheduling algorithm. It first calculates three important parameters namely maximum task instances per container, container capacity, and total task instances in the task graph.
int maxTaskInstancesPerContainer = TaskSchedulerContext.defaultTaskInstancesPerContainer(config);
int containerCapacity = maxTaskInstancesPerContainer * numberOfContainers;
int totalTask = taskAttributes.getTotalNumberOfInstances(taskVertexSet);
The first parameter represents the total number of task instances could be allocated to the container. The second parameter represents the total capacity of the capacity (number of available containers and the task instances to be allocated to the container). The third parameter represents the total number of task instances in the task graph (which is based on the number of total tasks and its parallelism). If the container capacity value is greater than total task instances, it is possible to schedule the task instances else, it will throw the task schedule exception and the task instances couldn't be scheduled to the available containers. The DataNodeLocatorUtils is a helper class which is implemented in
edu.iu.dsc.tws.data.utils.DataNodeLocatorUtils
which is responsible for getting the datanode location of the input files in the Hadoop Distributed File System (HDFS). If the index value is 0, the algorithm first calculate the distance between the worker nodes and the data nodes and store it in the map. Next, the algorithm send the task vertex and the distance calculation map to find out the best worker node which is based on the calculated distance. The distancecalculation() method in the algorithm get the network parameters (such as bandwidth and latency) from the workers property (if the network property is not null) else, the default value is assigned from the TaskScheduler Context. Then, it will allocate the task instances of the task vertex to the worker (which has minimal distance), if the container/worker has reached the maximum number of task instances it will allocate the remaining task instances to the next container. Once the container has reached its maximum task instance value, then the container is added in the allocated workers list (which represents that container has reached their maximum capacity and we can't any more task instances into the container). The procedure is same if the index value is greater than 0, but, the only difference is it has to calculate the distance between the worker nodes (which are not in the allocated workers list) and the datanodes. Finally, the algorithm returns the datalocalityawareallocation map object which consists of container and the task instance assignment details.
The DataLocalityStreamingTaskScheduler assign the logical container size based on the default ram, disk, and cpu values specified in the TaskScheduler Context. Then, the schedule() method unwraps the datalocalityawarecontainer instance map and finds out the task instances allocated to each container. Based on the task instances required ram, disk, and cpu it creates the required container object. If the worker has required ram, disk, and cpu value then it assigns those values to the containers otherwise, it will assign the calculated value of required ram, disk, and cpu value to the containers. Finally, the schedule method pack the task instance plan and the container plan into the task schedule plan and return the same.