architecture/README
Architecture
Goal of Twister2 is to provide a layered approach for big data with independent components at each level to compose an application. The layers include: 1. Resource allocations 2. Data Access 3. Communication 4. Task System 5. Distributed Data
Among these communications, task system and data management are the core components of the system with the others providing auxiliary services. On top of these layers, one can develop higher-level APIs such as SQL interfaces. The following figure shows the runtime architecture of Twister2 with various components. Even though shows all the components in a single diagram, one can mix and match various components according to their needs. Fault tolerance and security are two aspects that affect all these components.
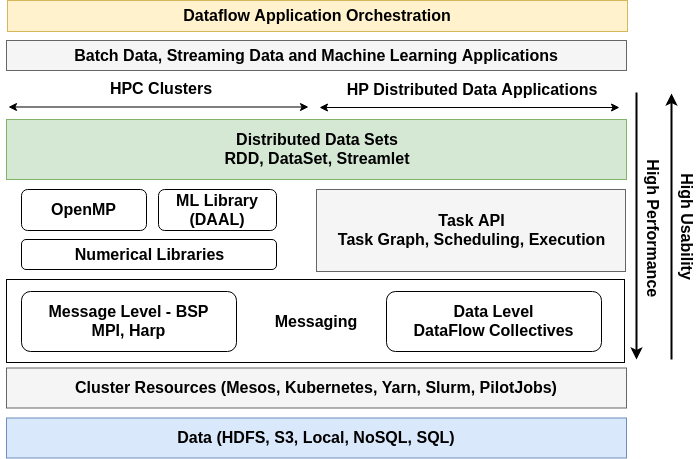
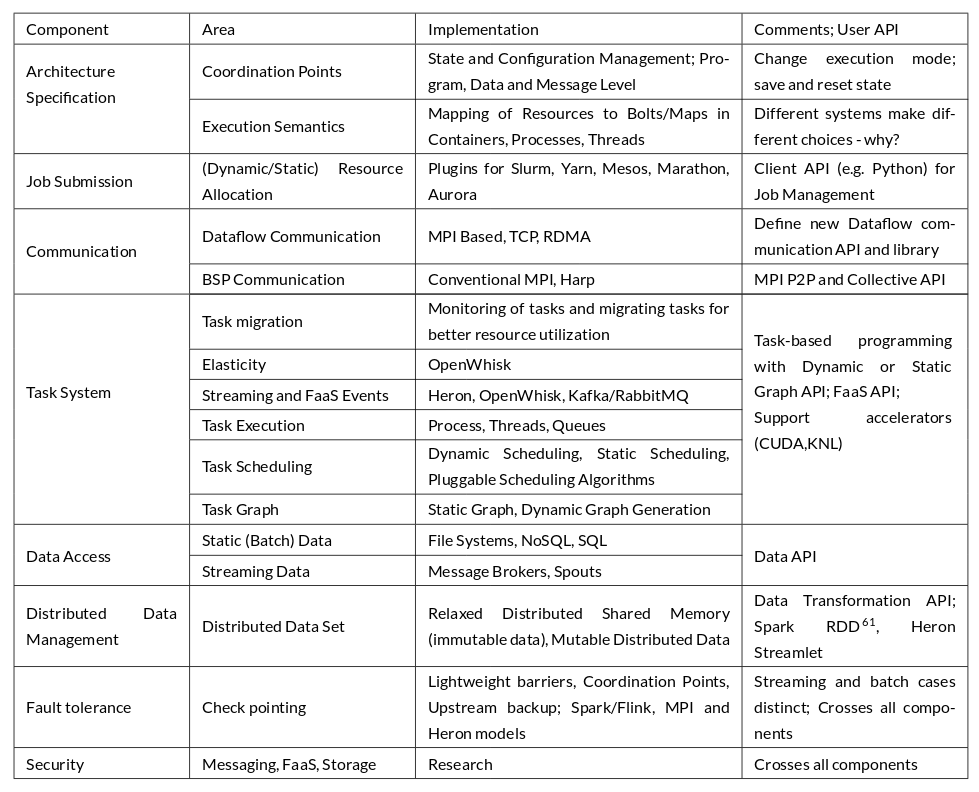
The following table gives a summary of various components, APIs, and implementation choices.
Twister2 Runtime
Twister2 Runtime consists of the following main components.
- Job Submission Client
- Job Master
- Workers
Job Submission Client
This is the program that the user use to submit/terminate/modify Twister2 jobs. It may run in the cluster or outside of it in the user machine.
Job Master
Job Master manages the job related activities during job execution such as fault tolerance, life-cycle management, dynamic resource allocation, resource cleanup, etc.
Workers
The processes that perform the computations in a job.
Twister2 Dashboard
Twister2 Dashboard is a web site that helps users to monitor their jobs. Only one instance of Dashboard runs in the cluster and it will provide data for all jobs running in the cluster. It is a long running service. It is installed and started once and it runs continually.
Following sections describe some of these components in detail.